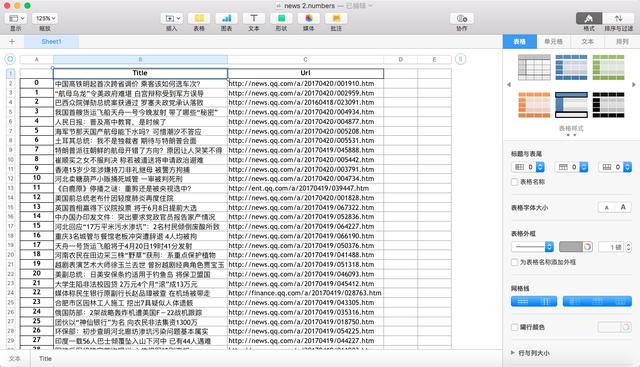
利用Python爬取腾讯新闻首页的标题和链接 Oct 26 2016 环境1、Python3 2、PyCharm 代码123456789import requestsimport pandasfrom bs4 import BeautifulSoupres = requests.get('http://news.qq.com/')soup = BeautifulSoup(res.text,'html.parser')newsary = []for news in soup.select('.Q-tpWrap .text'): newsary.append({'Title':news.select('a')[0].text,'Url':news.select('a')[0]['href']})newsdf = pandas.DataFrame(newsary)print(newsdf) 输出结果 将输出结果保存到本地Excel文件12345678910import requestsimport pandasfrom bs4 import BeautifulSoupres = requests.get('http://news.qq.com/')soup = BeautifulSoup(res.text,'html.parser')newsary = []for news in soup.select('.Q-tpWrap .text'): newsary.append({'Title':news.select('a')[0].text,'Url':news.select('a')[0]['href']})newsdf = pandas.DataFrame(newsary)newsdf.to_excel('news.xlsx') 结果 打开文件